

Developer News CLI App
A Ruby Command Line Application created as a project in the Flatiron Software Engineering program


I’ve learned a lot so far in my coding journey but I’ve learned more by starting and finishing my first project than I have at any other point so far. This project was a lot of fun and challenging!
I wanted to scrape data from some technology-focused websites that I visit and aggregate them. I wasn’t exactly sure how I would do it but I knew enough to get started and would take it one step at a time.
To make the project more manageable I separated it into two major areas, the CLI and scrapping the websites.
The requirements for the project were:
- Provide a CLI (Command Line Interface).
- The CLI must provide access to data from a web page.
- The data provided must go at least one level deep, generally by showing the user a list of available data and then being able to drill down into a specific item.
- The CLI application can not be a Music CLI application as that is too similar to the other OO Ruby final project. Also please refrain from using Kickstarter as that was used for the scraping ‘code along’.
- Use good OO design patterns. You should be creating a collection of objects - not hashes.
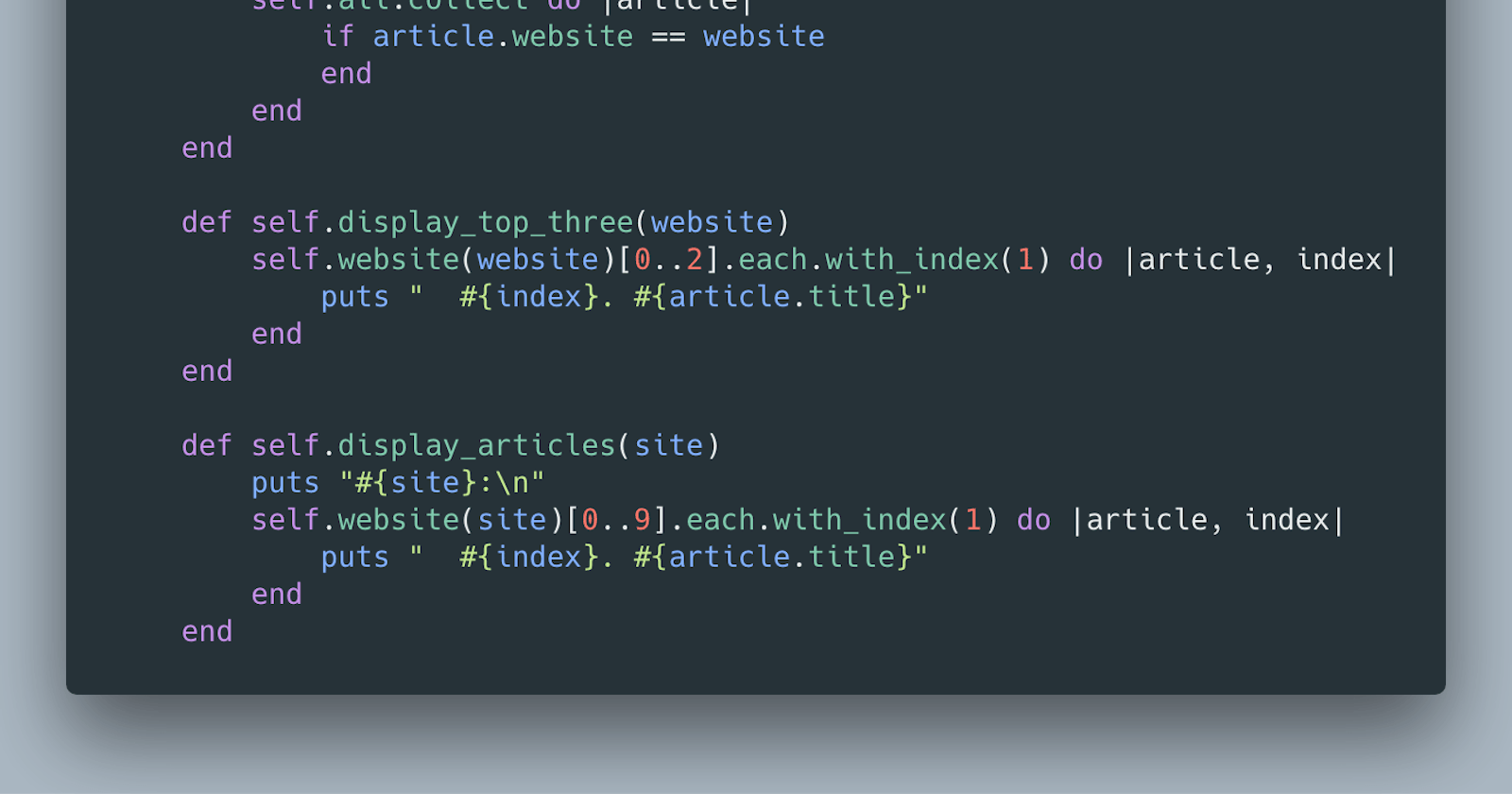
CLI Portion
I knew I wanted to scrape several websites to pull data about the articles on their homepages, but that would have to wait. At this point I wanted to keep things simple and just “stub-out” the CLI interface with fake data.
I went through several iterations of the interface but ultimately decided to let the user choose which website they would like to see articles from. From there the user would be presented with a list of article headlines and be able to choose which one they would like to see more information on. After drilling down to a detailed-view of the article, the user could copy the url to read in their browser. I also wanted to provide options to go back up one level or to the first level at any point in the interface.
Building the “go back” functionality was difficult at first. After struggling with this for a while I decided to take a step back and break it into smaller parts. I needed to know:
- What website the user selected
- Which articles belonged to that website

Keeping track of which website the user selected sounded like the responsibility of the CLI and keeping track of articles from a particular website sounded like a job for a scrapper class; specifically website-specific scrapper classes that would inherit functionality from a parent scrapper class!
Scrapping Portion
I used Nokogiri to scrape the websites. This part was challenging as well, but using Pry to insert breakpoints in the code helped a lot. Also, using the search function was helpful; which I learned at the Weekend Warriors Workshop last weekend!
It Works!
After working on this project for hours and hours over several days I was finally able to put all of the pieces together and have a working CLI Gem! This was an amazing feeling! I’ve learned a lot so far in my coding journey, but this was the first time that I felt like an actual programmer! Going from an initial idea or concept and bringing into fruition is exhilarating and fulfilling!
Added Feature
I must have ran the CLI Gem 100 time! After fixing some bugs and adding some styling changes, I decided I didn’t like forcing the user to copy/paste the article url in order to view it. There had to be a way to either put in the their clipboard, or better yet, open their browser to the article for them!
After Googling around and several rounds of trial and error, I was able to have the gem launch the user’s browser directly to the article…. and with one line of code!
def open_url(article)
`open #{article.url}`
end
The repository for this project is located here.
Overall, this was a fun and challenging project that pushed me to start with an idea and develop it into a working product!